

作者:李琪;转自:公号 DH数字人文
未来学者

李琪 / 北京语言大学汉语国际教育研究院
————————————
摘要: 以1946年至2015年《人民日报》的语料作为研究对象,通过文本统计以及历时比较,可以探讨语言生活随时代发展和受重大事件影响的变迁情况,并找到符合报刊语料的关键词提取方法。通过对历年报刊语料的预处理,利用高频共有词与高频独有词的提取方法、H-point和TextRank关键词提取方法以及隐含狄利克雷分布主题模型(Latent Dirichlet Allocation,简称LDA)的方法,分别对报刊语料进行关键词提取并进行分析,发现LDA与高频词相结合比较适合对报刊语料的关键词进行提取。将LDA提取关键词与高频词提取关键词相结合,可以更好地透过词汇对社会生活的变迁进行解读,同时有利于读者进行远距离阅读。这一研究表明,通过对语料的词汇研究,可以为报刊语料找到便于量化的研究方法,并尝试找到具有普遍性的计量统计研究范式。
关键词: 人民日报 时代精神 关键词提取 报刊语料研究 计量语言学
————————————
《人民日报》自创刊以来,见证了新中国历史进程中各个领域的发展和社会思想文化意识的变迁,其报道呈现了不同社会历史时期报刊语言的词汇特色,反映了现代汉语词汇系统随社会历史变迁而形成的动态演变过程,这为词汇系统历时演变研究提供了很好的观照视角,具有较高的词汇学研究价值。而且,定量分析方法能使我们对语料的历时研究有更加深刻、科学的认识。随着计算机技术和语料库语言学研究方法的发展,对数据的定量分析有了可靠的支撑。利用计量语言学理论和方法对报刊语料进行历时的定量研究,可以推动报刊语料的量化研究。本文以《人民日报》70年间的语料为研究对象,建设历时语料库,通过计量语言学的相关理论和定量分析的方法进行历时比较研究,描述语言生活随时代发展的变迁情况。通过对不同的关键词提取方法进行比较,确定了适用于提取报刊语料关键词来梳理年代事件的方法。
一、研究现状
本文中的“关键词”,是指能够反映文本主题或现象的词语,又称为特征词或主题词。对于关键词的研究主要涉及两方面:一方面是关键词提取的优化方法。陶洁在《基于新闻文本的关键词提取》[1]一文中以汽车新闻作为主题词提取语料,提出TextRank算法与Word2Vec模型相结合的方法,弥补了TextRank算法未考虑词汇节点初始权重的问题。王亚坤在《融合LDA与TextRank算法的主题信息抽取方法》[2]一文中则提出LDA与TextRank算法融合计算的思路,不仅提高了主题模型的信息表达能力,而且还将主题建模的准确率提高了2个百分点。
另一方面是利用关键词对语料进行具体地分析。张德阳在《基于主题的关键词提取对微博情感倾向的研究》[3]一文中综合考虑LDA和TFIDF值等统计特征,并针对七种不同的词性搭配对关键句的情感值计算进行了相应的探索。饶高琦、李宇明在《基于词频逆文档统计的词汇时间分布层次》[4]中基于70年历时语料,根据TFIDF的方法提取词汇,并利用历时语料按时间分布的性能、所提取的词语的词类和词长等特征对词汇进行时间分布统计,形成了基干层、过渡层、时敏层以及逸散层的词汇时间四分层体系。
词汇系统是一个多元而庞杂的系统,具有层级性、生成性以及历时演变的特点。随着社会生活不断的变迁,词汇系统也会发生相应的变化,其中最醒目的特征便是新词的出现和旧词的替换。由于一般正式报刊语料语言结构严谨,报道真实反映社会现实,因此成为大多数学者进行语言历时研究的首选语料。而《人民日报》作为中国最重要的党报之一,在传达党和政府的路线、方针和政策上一直具有前瞻性、权威性和指导性,从报刊语料的词汇使用中能够透视出中国社会政治、经济、文化的变迁轨迹。因此,进入21世纪以后,对于《人民日报》的研究日益广泛,现有的研究成果主要从以下三个角度出发:
一是历时变迁角度。刘晓丽《〈人民日报〉社论词汇统计与分析》[5]、龙美枞《1946—2014年〈人民日报〉常用词演变研究》[6]以及饶高琦、李宇明《基于70年报刊语料的现代汉语历时稳态词抽取与考察》[7]主要利用计量的方法对报刊语料的词汇进行定量研究,并透视出中国社会政治、经济、文化的变迁轨迹。刘燕燕《〈人民日报〉成语使用情况历时考察与研究》[8]和李彩玉《〈人民日报〉对坏消息报道的变化——以话语分析为视角》[9]则从话语分析的角度对报刊语料的词汇使用进行历时的考察,并发现社会的变化发展。
二是隐喻使用研究。周昕《〈人民日报〉(1949—2008)元旦社论隐喻研究》[10]主要利用定量与定性的方法筛选关键词并进行具体的隐喻考察。黄秋林、吴本虎《政治隐喻的历时分析——基于〈人民日报〉(1978—2007)两会社论的研究》[11]通过对30年的两会社论中概念隐喻的历时分析,探讨改革开放年代中国共产党如何阐述自己的执政理念。三是话语分析角度。刘昌伟、吴薇《中国话语十年变迁——以〈人民日报〉2000—2010年国庆社论为例》[12]主要从标题、篇幅分析社论的语言特色,并对国庆社论的发展变迁做简单的概括和梳理。
二、语料库建设
建设语料库是文本分析的基础。语料库语言学的发展为文本分析提供了全新的研究方法和思路,语料库已经成为文本定量分析的重要方法。本文以语料库语言学的相关理论和方法以及现代汉语词汇历时检索系统[13]为基础,建立1946年至2015年的《人民日报》历时语料库。
在进行报刊语料的定量对比分析之前,我们必须对语料进行加工和处理,主要包括语料整理、语料校对、分词和词性标注等。
《人民日报》1946年至2015年的报道格式不尽相同,对日期与题目的格式作一致性处理,便于后期计算机对文本的识别与计算。本研究所进行的语料加工主要包括语料的去重、去停用词、标注和校对。其中,文本的分词标注主要借助于Jieba分词工具,采用北京大学的分词和词性标注的标准。在人工标注校对过程中,我们集中对引号包括的短语进行校正。整理加工后的具体信息如图1:

三、时间通用词提取
张普认为:“语言应用的两种状态是‘稳态和动态’。”[14]稳态表示的是一种相对静止的状态,而这一点适用于在时间维度上考虑词语的分布状态。饶高琦则将词汇系统中处于稳定状态的词语特征概括为:具有“使用稳定、受时间影响小、更新和变异缓慢、构成现代汉语词系统的底层、起到基础和主干作用”[15]。结合报刊语料具有历时性的特点,我们选取了俞士汶提出的词的分布均匀度(Distribution Consistency,简称DC)计算指标,但由于考察的是一定时间范围内某一词语的通用程度,赵小兵则将在一定时间范围内计算某一词语分布均匀度的指标称为“时间通用度”[16]。因此,我们提取70年报刊语料中时间通用度高的词语,作为符合稳态特征的词语。具体计算方法如下:

K号词语的时间通用度:TK=SMR/Mean(0 ≤ TK ≥ 1)(公式3)
n表示考察时间内年个数,要求各年的语料等量,FKi是词语在第i年的词的频度。时间通用度越高,则该词语在考察时间范围内使用越稳定。

表1 《人民日报》时间通用度部分统计表

从图2中,我们可以看到历年新闻篇数不同,且差异较大,而1946年的新闻篇数最少。为了使获取的时间通用词能够最大程度地覆盖每年的新闻报道,以1946年的新闻报道总篇数5,859,作为70年中每年等量语料抽取的标准。
表2 《人民日报》高时间通用度部分词表
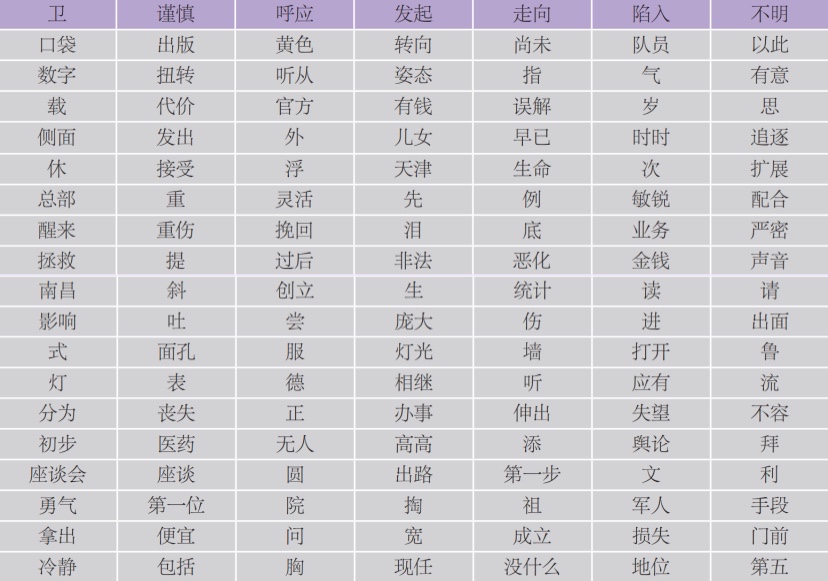
我们提取时间通用度高于0.6的词语作为基础词(如表1),有利于减少在提取关键词时的噪音。例如,表2中“黄色”“谨慎”“发起”“陷入”“接受”“胸”“姿态”等形容词、动词以及名词在70年的报刊语料中经常出现,但是本身携带的关键信息相对较少。所以,将这一部分基础词在后续提取关键词时去掉,可以在一定程度上提高关键词的质量。
四、共有词与独有词
根据每年《人民日报》语料,利用哈工大的停用词表以及前面获得的时间通用度词表,对语料进行加工,得出每年《人民日报》的高频词表。通过高频词表,运用共有词与独有词来提取历年关键词,试分析社会热点事件,发现社会发展脉络以及用词变化。
每个年份均按照频次排序取前500的高频词,以十年为一界限,统计了每十年的高频共有词和独有词。共有词指这十年的高频词中共同出现的词,独有词指与前一个十年相比,后十年新出现的词语,独有词并不是新产生的词语,而是与之前的年份相比,更高频使用的词语,能在一定程度上反映事物概念的重要程度。
(一)共有词研究
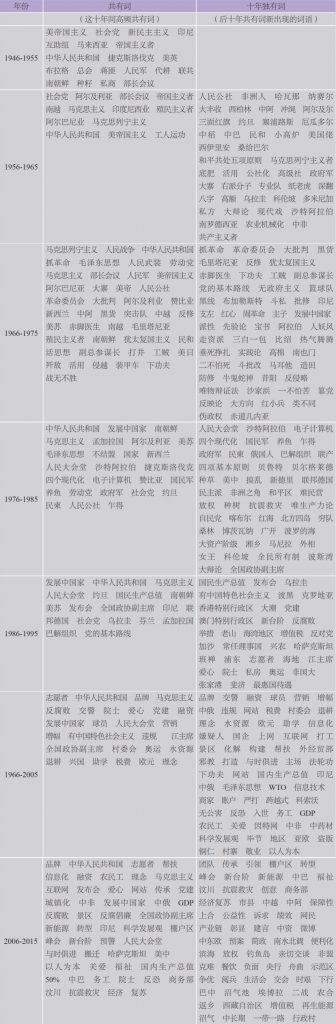
从表3看出,1946到1995年间有关国家和党派的词语出现较多,如1946到1955年间有美帝国主义、社会党、新民主主义、印尼、马来亚、中华人民共和国、捷克斯洛伐克、美英、布拉格、南朝鲜等;1956到1965年间有阿尔及利亚、南越、印度尼西亚、阿尔巴尼亚、中华人民共和国、美帝国主义、南朝鲜、捷克斯洛伐克、亚非国家、锡兰、美英、哈瓦那等;1966到1975年间有中华人民共和国、劳动党、美帝国主义、阿尔巴尼亚、美帝、阿尔及利亚、赞比亚、新西兰、中阿、中越、美苏、南越、毛里塔尼亚、南朝鲜、美日等。这表明在这个时期,《人民日报》更多报道我国与其他国家间的关系或者其他国家的状况。
而在1996年及以后,《人民日报》的报道很明显地集中在国内的发展与本国的建设问题上。首先,“融资”“营销”等词语反映出我国重视经济发展以及经济发展形式的多种多样。如“品牌”体现了我国对发展市场经济的重视与消费市场的发展,“国内生产总值”体现了国家对快速发展本国生产力的重视与要求。其次,在本国的建设过程中,“志愿者”一词高频出现。与之前相比,“志愿者”的大规模出现显示出我国对青年的期待与要求,在国家经济、生产力的恢复时期,希望广大青年投身到社会各方面的建设中,为祖国奉献助力。此外,这个阶段的重大历史事件也能够通过词语反映。比如,1986至1995年间已经开始逐渐重视反腐败问题,“反腐败”一词在1996年已出现在中央文件中,当时成立了“中央反腐败协调小组”,开始严厉打击腐败现象,此后“反腐败工作”相关词汇一直出现在1996至2015年间的高频词中;频繁使用“水资源”“退耕”等词语,表明国家将自然资源的保护提上日程;1996至2005年间的高频词中,出现了“交警”“院士”“球员”等职业词语,可见《人民日报》对这些职业给予更多的报道和重视,不同的职业也分别象征了不同的职业精神对国家发展的重要性。
表3 《人民日报》每十年共有词、独有词词表
(二)独有词研究
独有词是指一个新的阶段新出现的高频词,体现了对一个新事物或新概念的重视,此后这一新表达或继续发展,留存在高频词中,或逐渐成为报刊的边缘话题,慢慢消失。继续发展的独有词便大量出现在历年的共有高频词中,如“反腐败”“人民公社”“奥运”等。1956至1965年的十年与前一个十年相比,独有词中有“人民公社”,其重要性不言而喻。我国第一个人民公社在1958年成立,此后在我国农村建设和发展中具有指导性的现实意义,是我国探索社会主义建设道路中的一项重大决策。“奥运”第一次出现在1986到1995年间的独有词中,我国在1990年首次申请承办2000年的奥运会,但于1993年落选,此后并未放弃继续申请承办,终于在2000年申奥成功,代表了我国以崭新的面貌迎接新世纪。此外,“电子计算机”首次高频出现在1976至1985年间,其时正是我国计算机事业的起步阶段,1996至2005年间计算机事业蓬勃发展,“网站”“信息化”“上网”“互联网”“信息技术”一下子涌入时代新词中,可见改革开放使计算技术涌入了市场经济的大潮。
逐渐消失的高频词占比更多,它们往往能够体现一个年代的特征或中国在某一时期的发展状况。如1966至1976年文化大革命期间,高频出现的独有词基本能够反映这一时期的特征,“抓革命”“革命委员会”“大批判”“反修”“赤脚医生”“工贼”“斗私批修”“支左”“红心”“闹革命”等,有着特殊历史时期的烙印。此外,从对一些国家和人物的称呼中也能够看出中国在不同时期的情感极性的差异,如对美国的称呼变化有美帝/美帝国主义、美国佬、美等。
通过《人民日报》每十年的共有词与独有词,可以看出社会发生的热点事件以及国家发展的重要政策。但是我们无法从高频词表中看到社会发展的连续性,不能确切地判定社会发展的基本脉络。
五、基于h点的关键词提取
接下来,利用计量语言学中的文本计量指标——h-point,即h点来统计每年报刊语料中的主题词。h点是语料中词语的秩频分布的一个临界点。刘海涛在《计量语言学导论》中指出:“h点之前的词大多为功能词,但仍有一部分实词。这些实词往往与文本的主题有关,因此称为主题词。”[17]我们则利用计算h点的方法,获取高频关键词。

在图3中,可以直观地看出,h点是词的秩频分布上满足y=x的那个点。在h点前的词频序满足r1 < f(r1), 反之,处于h点后的词满足r2 > f(r2),则一定存在处于h点前后的两点构成的直线与y=x的交点为h点。因此,解方程得到:

由于我们获取的70年间的《人民日报》新闻篇数不一致导致每年的文本大小不尽相同,而h点受文本大小的影响显著,为了减少文本大小的影响,我们选择使用前文中已经处理好的以1946年新闻篇数作为历年等量文本标准的语料,并利用文本计量指标的分析工具QUITA来计算h点的值,最后用h点统计出h点之前的所有词语,同时去掉停用词,获得历年关键词表(表4)。
通过基于h点的历年《人民日报》高频关键词表,我们发现1946到1980年间,“革命”一词伴随着“军队”“解放军”“斗争”“大跃进”“美国”“苏联”时常出现,1981到2015年间“改革”一词则伴随着社会的“政治”“经济”“建设”出现。
1946至1980年间,国家处于成立初期。在新社会制度代替旧制度的过渡时期,革命往往采用武装斗争的形式,同时还需要不断维护、巩固中央的统治。从表4中的部分高频关键词中,我们可以看到,在1948年、1949年、1952年、1953年存在“自卫”“斗争”“美帝国主义”“官僚”“总路线”“无产阶级”“资产阶级”等一类反映武装斗争、阶级斗争、意识形态等问题的词语。而1981至2015年期间,新的社会制度需要持续存在并获得一定程度的发展,为了解决生产关系不适合生产力、上层建筑不适合经济基础的某些部分或环节的矛盾,使该社会制度得以自我完善或持续发展,国家逐渐关注社会精神文明建设,不断地改善民生,在政治、经济、文化、生活的方方面面进行制度调整与完善。根据表4统计的关键词,我们也可以发现,“价值观”“教育”“思想”“创新”“市场”“中国梦”“文化”“政策”“路线”“环境”“经济”等反应社会各方面的词语在社会改革期间不断地出现。
表4 基于h点的《人民日报》关键词部分词表

透过每年的高频关键词,我们也可以发现一些重大事件的端倪。比如,通过表4,我们可以看到1948年的“蒋匪”“解放军”反映了当时正处于内战时期;1952年的关键词中出现“志愿军”“美国”“美帝国主义”“朝鲜”“抗美援朝”,反映出朝鲜战争的爆发,国家出于自卫派兵援助朝鲜;2010年出现“能源”“节能”“西部”等词,反映了国家关注节能减排,并且提出新型能源产业振兴规划,要求大力发展新能源,关注生态问题,同时该年关键词中还出现了“上海世博会”,这是展现国家综合国力提高的大事件;2014年词表中出现“参拜”“靖国神社”“日本”,参拜靖国神社一直是我国强烈反对的,也预示中日两国关系的走向,同年关键词词表中还出现了“中国梦”“文明”“中华民族”“价值观”“精神”,这一时期我们国家高度重视社会主义精神文明建设。
通过统计基于h点的《人民日报》高频关键词,我们可以初步看到国家发展的基本脉络是从革命到改革以及期间伴随着国际社会格局的变化和我国对外方针的变化。同时,利用高频关键词表,我们也可以看到当时社会重大事件。基于h点提取的关键词以及高频共有词和独有词,都是从文本选取的当年频次较高词语,可以反映当年的大事件,但是无法向我们展现当年社会的完整面貌,我们只能从单一事件中去解读。另外,尽管高频词的提取方法有很多,但是都无法避免其取值受文本总量的影响。
六、基于无监督学习的关键词提取
在借助计算机提取关键词时,无监督学习是一类重要的方式,主要包括三种具体的方法:一是利用词频以及词语的位置信息等特征的TFIDF算法;二是利用图论、矩阵等数学知识的图模型,即TextRank算法;三是将概率分布以及贝叶斯先验理论运到主题模型中的LDA模型。现采用TextRank算法和LDA模型进一步对《人民日报》关键词进行提取和解读。
(一)基于TextRank算法的关键词提取
TextRank算法是一种基于谷歌PageRank算法的图排序算法。其中心思想是词语的重要程度以及对文本的影响程度是由相邻词语通过连接或指向别的词语进行传播表现出来的。具体来说,某一个词语被连接或指向的较多,则说明该词语是关键词的概率比较大。其具体算法为:

其中,Vi、Vj表示任意两点,Wji表示两点之间边的权重,Out(Vi)是指向点Vi的集合,d为阻尼系数,一般取值为0.85。我们使用Jieba工具包中的TextRank来提取每年前40个关键词。
表5 基于TextRrank的《人民日报》关键词部分词表

表5是1966至1974年的关键词,我们发现“中国”“人民”“群众”“进行”等词语不能提供给我们过多的关键信息。而词表中的“思想”“政治”“建设”“革命”等虽是反映社会多个方面的词语,但是无法利用这些词语给社会勾勒画像。于是,我们将《人民日报》历年的前40个关键词做了词频高于或等于20的词频统计图。
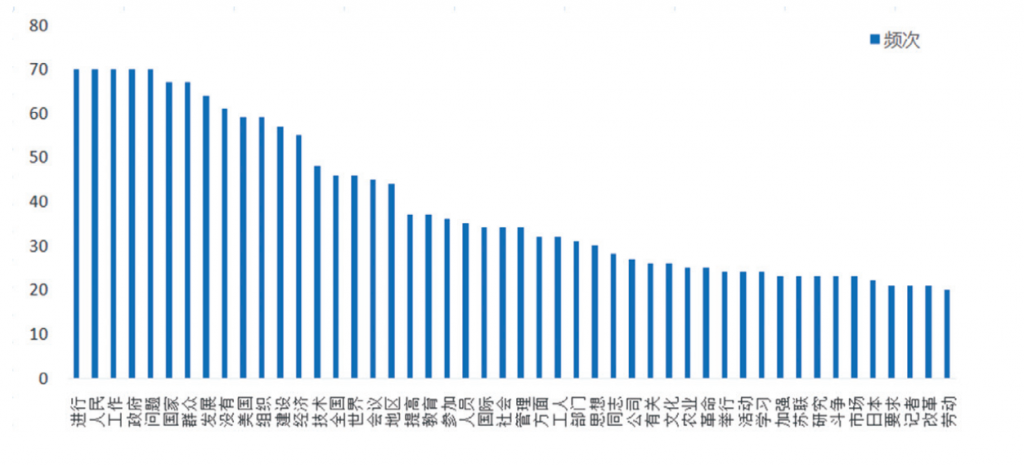
如图4所示,“进行”“工作”“问题”“人民”“国家”等词语在这70年都有出现。而“进行”“问题”“没有”“全国”等这一类高频出现且较少携带关键信息的词,属于前文中我们所定义的高时间通用度的词。我们将这一类词语进行筛选,发现剩下的词语大多是“技术”“经济”“美国”“斗争”这一类可以说明当年社会正发生变化、但无法进行具体描述的词语,如下表:
表6 基于TextRank的《人民日报》非稳态关键词词表
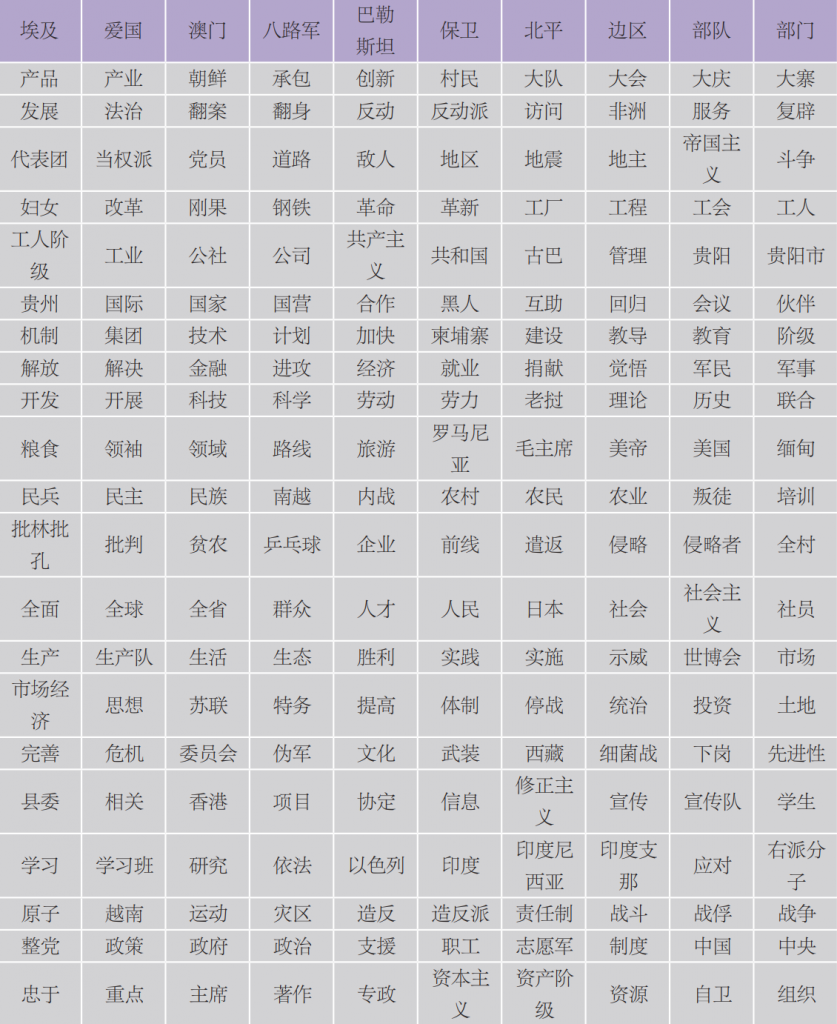
基于TextRank获得的关键词在一定程度上受算法特点即被连接得多或是被指向得多的影响,尽管我们筛选掉处于稳态的那一部分词语,获得的还是具有高度概括性以及无法反映具体大事件的词语。因此,利用TextRank算法来获取关键词并进行解读不适用于长文本。
(二)基于LDA主题模型的关键词提取
“单一使用无监督学习的任何一种方法,在提取关键词的准确率上都不会有特别出色的表现。”[18]因此,我们主要利用Scikit-learn工具中的LDA主题模型获取主题以及相应主题词下的特征词,并结合TextRank算法获取的非稳态关键词以及《中文新闻信息分类与代码》进行机器与人工辅助的聚簇主题识别,最后利用历年不同主题下的关键词去勾勒社会变迁的情况。
(三)LDA主题模型的聚簇主题识别
隐含狄利雷分配模型(Latent Dirichlet Allocation,简称LDA)是一种生成模型,涉及到概率分布和贝叶斯先验理论等知识。同时LDA主题模型包含了文档层、主题层以及词汇层,具有清晰的层次结构。假设有D篇文档,其潜在的LDA模型的形式化表示为:
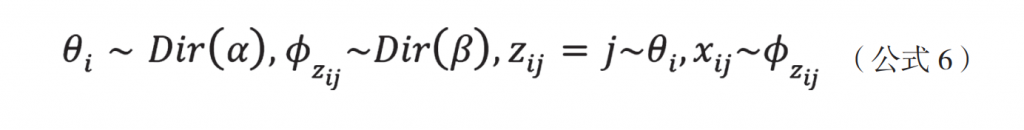
其中Dir()是狄利克雷分布,α与β是Dir()的参数。即一篇文档生成的方式为:从狄利克雷分布α中取样生成文档i的主题分布θi,主题分布θi是多项式分布;在多项式分布θi中文档i第j个词的主题是Zij;从狄利克雷分布β中取样生成主题Zij对应的词语分布为φZij,从而在词语的多项式分布中φZij最终生成词语xij。
我们运用Scikit-learn工具包中的LDA来获取70年的关键词,前提是取得最优主题数。在scikit-learn工具包中,可通过计算LDA模型的困惑度(Perplexity)来取得最优主题数。为了减少新闻报道篇数不同带来的差异,我们选取1946年的《人民日报》语料,并利用Scikit-learn工具包中的LDA困惑度来确定主题数。

从图5中可以发现,困惑度曲线在拐点之后其值趋于平缓。根据困惑拐点值来确定主题数,则该年的主题数为95。以1946年的95个主题为基础,利用Scikit-learn工具包求每年《人民日报》95个主题并输出每个主题下权重较高的前20个词。
表7 基于LDA的某年《人民日报》部分主题及关键词
表7是某年第60号至第79号主题,从表7中不同主题下的关键词可以看出,一些主题涉及的内容是重合的。例如,第60号与第64号主题都涉及文艺休闲生活;第61号、第63号以及第76号主题都涉及外交;第66号、第67号、第70号、第74号以及第79号主题都涉及生态环境与气候。所以,我们需要将这一类重合的主题进行合并。由于人工识别工作量较大,因此我们把前面整理的TextRank非稳态关键词表的词语根据语义结合《中文新闻信息分类与代码》一书中新闻信息分类原则进行分类,并将分类后的关键词作为机器识别聚簇主题的关键词。通过不断地用程序识别内容有所重合的主题,发现有未识别的主题出现。在查看未识别的主题后,将该主题词簇下权重较高的词作为关键词,添加到机器中。经过多次循环后,我们将95个主题整合成32个主题,具体如下表8:
表8 基于关键词识别的聚簇主题统计表

(四)基于《人民日报》聚簇主题的社会变迁解读
饶高琦、李宇明运用聚类的方法对《人民日报》作了“两段三层”的分类,[15]三层即1946—1979年是新政权的过渡和稳定期、1980—1999年是十年浩劫结束的过渡期以及2000—2015年是改革开放全面发展的新时期,而“两段”则是1946—1979年以及1980—2015年。我们将聚簇主题识别后的语料分别进行了同一主题在不同年代出现的历时统计,如图6,以及整理了同一主题下的关键词词表,如表9,并利用“两段三层”的分类对《人民日报》70年的语料进行解读。
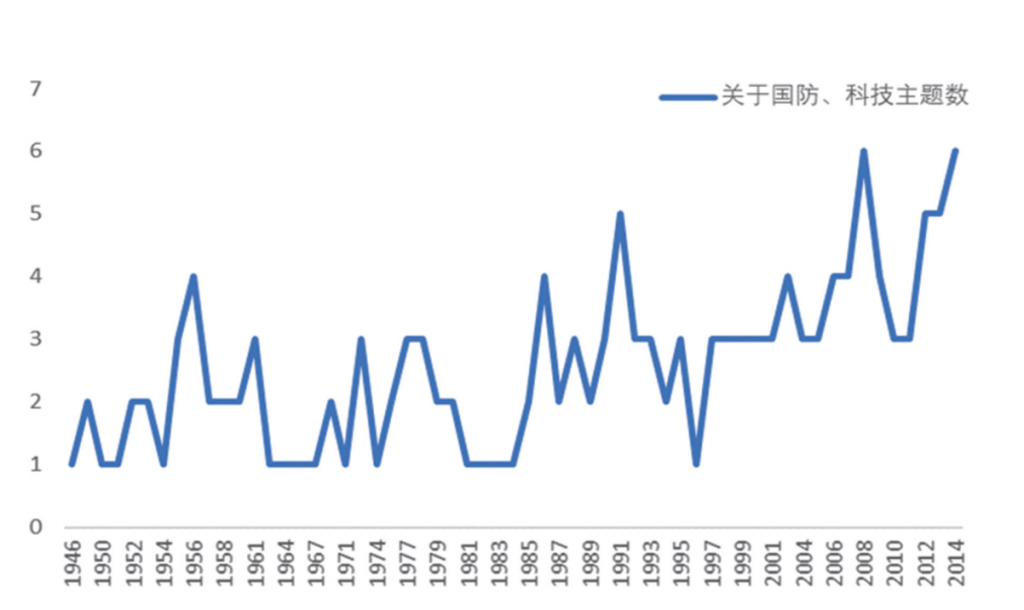
表9 《人民日报》部分年份同一主题的关键词词表(以国防、科技为例)
根据表9以国防、科技两个主题为例,并结合图6,我们利用“两段三层”70年的分期,可以知道从新中国成立之初到我国各方面飞速发展的阶段,国防与科技这两个主题数在《人民日报》中呈现上升的趋势,在1946至1979年国防与科技两个主题数发展趋势起伏较大。国家发展的初期政治、经济、文化等各方面在曲折中发展,“三大改造”“五年计划”等经济政策的出台推动了经济的发展,为国防与科技的发展提供了坚实的物质基础。同时,1960年代社会发展缓慢,在一定程度上遏制了我国国防科技力量的提高,但仍值得庆贺的是,“两弹一星”成功使我国成为少数掌握核力量与空间技术的国家。1980至2015年,国防与科技主题数的变化趋势起伏相对较小且上升趋势突出,其间包括社会恢复发展阶段以及改革开发建设初期与稳步发展时期。这一时期“科教兴国”战略以及义务教育的普及推动了教育事业的大力发展,为培育科技人才奠定了基础。同时,“百人计划”“千人计划”培育建设了一批海外高层次人才创新创业基地,也推动了我国高新技术的跨越式发展。改革开放以来,我们的神舟载人航天工程、“嫦娥探月工程”“蛟龙号”载人潜水探测器以及北斗卫星导航系统等无不彰显着我国国防科技的力量。
表10 《人民日报》部分年份国防、科技主题的关键词词表(涉及太空、海洋领域)

利用表9中国防、科技两个主题的关键词,在运用LDA整理的历年主题词表中,我们检索了每年国防、科技两个主题下,有关太空、海洋两个领域的关键词,如表10所示。从1950年代开始,《人民日报》一直关注着太空领域的新闻,并于1970年代开始关注海洋领域的发展。在此表中从1950年代的“人造卫星”“火箭”“苏联”到六七十年代出现“苏联”“美国”“宇宙飞船”“月球”“宇航员”“季托夫”,再到八九十年代的“美国”“苏联”“空间”“航天飞机”。我们发现《人民日报》关于太空领域的报道是从美苏军备竞赛开始的。这一时间段太空领域的发展脉络大致总结为:从苏联人造卫星的发射成功,到美苏研制宇宙飞船和航天飞机并成功登上月球,再到美苏着手空间站的建设。随着美苏在太空领域的发展,在词表中,可以看到我国太空领域的发展轨迹,从1970年代初第一颗人造卫星的顺利发射,到八九十年代气象卫星的出现以及通讯卫星的研发,再到21世纪我国载人航天工程“神舟”载人火箭的成功、探月工程“天宫”“嫦娥”一系列卫星的出现,推动了我国向太空探索的进程。
对海洋领域的关注,从1970年代“钓鱼岛”“西沙群岛”“南海”“主权”“领海”,到八九十年代“海洋”“勘探”“资源”“南极”“长城站”“考察队”,再到21世纪的“编队”“护航”“巡航”“钓鱼岛”“蛟龙”“潜水器”等词,可以看到《人民日报》对海洋的关注有明显两个方向。一是在国防主题下,关于领海主权的问题。二是在科技主题下,关于海洋与气候之间的问题以及海洋资源的勘探,例如,南极科学考察、“蛟龙号”潜水器的成功下水。
结 论
《人民日报》作为权威报刊,其报道内容反映着国家对内对外的各种方针政策。从用词角度对《人民日报》做历时定量分析,提取历年语料的关键词,可以帮助我们发现重大事件发生的年代以及社会变化的趋势。利用基于高频词提取和无监督学习的方法提取关键词,可以在一定程度上体现社会发展不同阶段的重大事件,感知社会不同方面的发展趋势,描述社会发展各方面的具体面貌。通过提取《人民日报》的关键词,我们还可以进行一系列的词汇研究。例如,我国对美国、苏联等国家的情感变化以及我国对经济、文化、思想等政策变化的历时研究。可以说,历时关键词提取对历时语言发展和计算历史研究进行了基础数据补充。
—————————————————————————————————————————————————————–
The Spirit of Era: The Extraction and Interpretation of Diachronic Context Key Words
Li Qi
Abstract: This article takes the corpus in People’s Daily from 1946 to 2015 as studying objects. Through the contextual statistic and diachronic comparison, it discusses the evolution that language life is developing through different eras and influenced by 149 significant events so as to find the methods to extract key words which are in accordance with journal corpus. Through the pre-treatment of journal corpus over the years and using the method that extracts both shared words and highly frequent unique words, the methods of H-point and TextRank that extract key words as well as the theme model of Latent Dirichlet Allocation (LDA), this article respectively abstracted the key words from journal corpus, conducted analysis, discovered that the combination of LDA and highly frequent words is more suitable for the extraction of key words in journal corpus. Combining LDA and highly frequent words to extract key words, it is better to interpret the evolution of social life through the words. At the meantime, it is also easier for readers to read from a distance. The purpose of studying the corpus words is to find the studying methods which can be easily quantified for journal corpus and to find the universal statistical studying paradigm.
Keywords: People’s Daily; Spirit of Era; Keywords Eextraction; Research on Newspaper corpus; Quantitative Iinguistics
—————————————————————————————————————————————————————–
编 辑 | 王波
注释:
[1]参考陶洁:《基于新闻文本的关键词提取》,博士学位论文,华中师范大学,2019年。
[2]参考王亚坤:《融合LDA与TextRank算法的主题信息抽取方法》,博士学位论文,山西大学,2017年。
[3]张德阳、韩益亮、李晓龙:《基于主题的关键词提取对微博情感倾向的研究》,《燕山大学学报》2018年第6期。
[4]饶高琦、李宇明:《基于词频逆文档统计的词汇时间分布层次》,《中文信息学报》2019年第11期。
[5]参考刘晓丽:《〈人民日报〉社论词汇统计与分析》,博士学位论文,广西师范大学,2015年。
[6]参考龙美枞:《1946—2014年〈人民日报〉常用词演变研究》,博士学位论文,暨南大学,2018年。
[7]饶高琦、李宇明:《基于70年报刊语料的现代汉语历时稳态词抽取与考察》,《中文信息学报》2016年第6期。
[8]参考刘燕燕:《〈人民日报〉成语使用情况历时考察与研究》,博士学位论文,河北大学,2014年。
[9]参考李彩玉:《〈人民日报〉对“坏消息”报道的变化》,博士学位论文,浙江大学,2007年。
[10]参考周昕:《〈人民日报〉(1949—2008)元旦社论隐喻研究》,硕士学位论文,华东师范大学,2009年。
[11]黄秋林、吴本虎:《政治隐喻的历时分析——基于〈人民日报〉(1978—2007)两会社论的研究》,《语言教学与研究》2009年第5期。
[12]刘昌伟、吴薇:《中国话语十年变迁——以〈人民日报〉2000—2010年国庆社论为例》,《新闻世界》2011年第3期。
[13]荀恩东、饶高琦、谢佳莉:《论语言的稳态》,《中文信息学报》2005年第3期。
[14]张普:《论语言的稳态》,《郑州大学学报》(哲学社会科学版)2008年第2期。
[15]饶高琦、李宇明:《基于词频逆文档频统计的词汇时间分布层次》,《中文信息学报》2019年第11期。
[16]参考赵小兵:《基于动态流通语料库的现代汉语基本词汇自动识别与提取方法研究》,博士学位论文,北京大学,2007年。
[17]刘海涛:《计量语言学导论》,北京:商务印书馆,2017年,第134页。
[18]徐立:《基于加权TextRank的文本关键词提取方法》,《计算机科学》2019年第S1期。
原刊《数字人文》2020年第3期,转载请联系授权。